Git vs Subversion
Probably every software project nowadays relies on a version control system to manage the evolution of the code and coordinate concurrent changes. Since the development of the pioneer CVS by the GNU project, solutions such as Subversion, Git and Mercurial have emerged. They certainly improved over the multiple limitations of CVS and provide additional new features. While I never had the chance to use CVS, I have quite some experience with its successor Subversion. In the last years, though, Git has gained a lot of adherents. The project, initially conceived and developed by Linus Torvals, was developed for the Linux kernel back in 2005. The popularity of Git nowadays is palpable. As of 2015, GitHub reports 9 million users and 21 million repositories. Prominent software projects such as JQuery, Ruby on Rails and Joomla! are hosted in GitHub. I was also dragged by this boom when one of the contributors of the J!Research project proposed me to migrate the source code to GitHub. This naturally forced me to become familiar with this version control system.
The key point of Git is its distributed architecture. Subversion or CVS, in contrast, have a centralized architecture.
What does it means distributed?
Subversion has a traditional client-server architecture. An administrator creates a master repository in a server (svnadmin create) and the clients create local copies of this repository (svn checkout). There is a clear distinction between the master repository hosted in the server and the local copy of the clients. Clients can make changes to the code in their local copies and once they are confident those changes make sense, commit them to the repository, so that their changes become visible to other developers (svn commit). This setup can naturally lead to conflicts, if for example two clients change the same piece of code in a different way. The last submitter will be warned of a conflict which he will have to solve manually. Moreover, clients can at any moment update their local copies with respect to the master repository (svn update).
In Git there is, in principle, no notion of master repository. Once a repository is created (git init), every developer will create a clone (git clone), which is structurally identical to the initial one. User can make changes in their cloned repositories, e.g., add files (git add), change code, and then commit (git commit). The key is that their commits are performed against their local repositories. While this may sound bizarre to a SVN user (it happened to me), it conveys an interesting advantage: users do not need connectivity to enjoy from version control. If a user committed multiple times to his local repository, he can always come back to what he wrote several hours ago (git reset or git revert, to understand the difference check here). This is not possible in Subversion without having to contact the remote repository. This setup, on the other hand, implies that a git commit command does not make a user's changes visible to other users.
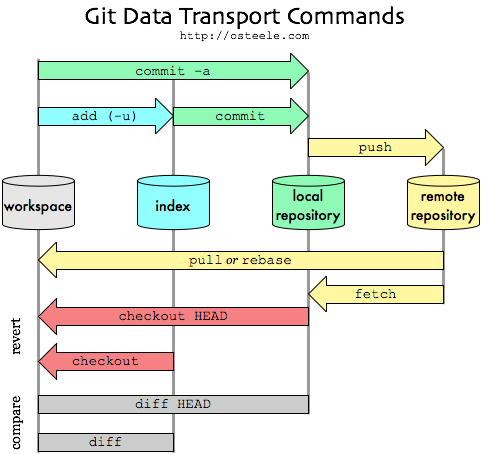
In practice projects using Git have one clone of the repository accessible to everybody, a master repository. To make changes visible in the master (remote repository), a user needs to perform a push operation (git push). The following picture taken from Oliver Steele's blog shows the typical data transfer flow when using Git.
Branching and tagging
A branch is a side-line of development created to develop features in isolation. Branches have usually a lifetime, because the features implemented there will be eventually merged into the main development line. In the Subversion jargon, the main line is known as the trunk. Once the features implemented in a branch are ported to the trunk, there is no reason to keep the branch. Conversely, tags are snapshots of the main development line that are kept to store the exact state of the code at the time of certain milestone, e.g., a software release. It is a widespread convention in the Subversion world to organize the repository in 3 subdirectories: trunk/ (main development line), branches/ (with one subdirectory per branch) and tags/ (also one subdirectory per tag). Although branching and tagging seem as different operations, they are actually implemented as simple copy operations in Subversion, that is, a branch or a tag is a copy (svn copy) of the trunk directory. It is important to remark that Subversion stores branches as cheap copies. This means that Subversion does not actually copy the entire directory, but creates a new independent pointer for the folder of the branch. When the branch is created the new pointer points to the same place as the trunk pointer, however, as changes are committed to the branch, the branch pointer will move forward in a different path. This also implies that a file created from a svn copy operation will share part of the timeline with the object from which it was originated. Although copy operations are space-efficient in the server side, the client will still have to get a local copy of the branch via svn checkout.
In Git, branching and tagging are built-in operations. Every repository has a default branch called the master. When a repository is created (either via git init or git clone), any commit operation will affect the master branch. This is equivalent to say that at repository creation the master branch is the active branch. The creation of a new branch is achieved via the command git checkout -b <branch_name> (-b creates a new branch). If you are a Subversion user, you will probably find it confusing as the word 'checkout' has a completely different meaning in Git. It is also important to know that git checkout will make the new branch the active branch. All changes made from now on will be committed towards the newly created branch. The very same git checkout command (without the -b) can be used to switch between branches including the master. When you switch to a branch, Git takes care of making your workspace look like the last time you committed in that branch. Merging two branches is also fairly easy: git merge <branch_name> will merge the active branch with the branch provided as argument. Tagging is also trivial: git tag <tag_name> <commit_id> does the trick. Here <commit_id> is the id of the last commit operation we want to include in the tag. I emphasize that all these operations are very cheap and do not required access to the network since all the branches are stored locally. To make our tags and branches visible in the remote repository we resort again to the command git push.
One of the most interesting features that I discovered in Git is what is known as rebasing. It came to be very useful for my work in J!Research. The standard scenario is that I have at least 2 branches, namely, the master containing the development line for the next upcoming release, and one or more experimental branches where I start implementing features for future releases. It happens often that I discover bugs in the experimental branches, that should be fixed also in the master. The command git rebase offers the possibility of taking a set of changes made in one branch and replay them in another branch. That said, I can simply fix the bugs in the experimental branch and replay them in the master. In Subversion, the standard solution would be to generate a patch from the experimental branch and apply it to the trunk.
For a really pedagogical and concise description of the git commands, I recommend you to go here.
Which are the drawbacks of Git?
The advantages of Git come at a price of course. The first natural observation is its complexity with respect to Subversion, which entails a more flat learning curve. The additional complexity does not pay off for projects with a few developers/low concurrency of changes, or in cases when connectivity is really not an issue. In addition, for huge repositories, SVN is more suitable because it allows clients to create local copies for subdirectories, something is not possible in git. This particular observation also implies that is not possible to implement access control mechanisms to certain areas of the repository (at least not out of the box). Finally I have read multiple complains about the immaturity of the Git tools in Windows, however I cannot witness this fact as I am not a Windows user.
Conclusion
For projects with high throughput and big communities such as the Linux Kernel or Joomla! or for those who require off-line control version, the advantages of Git are pretty attractive. If not the case, Subversion offers all what a project needs for effective control version.